
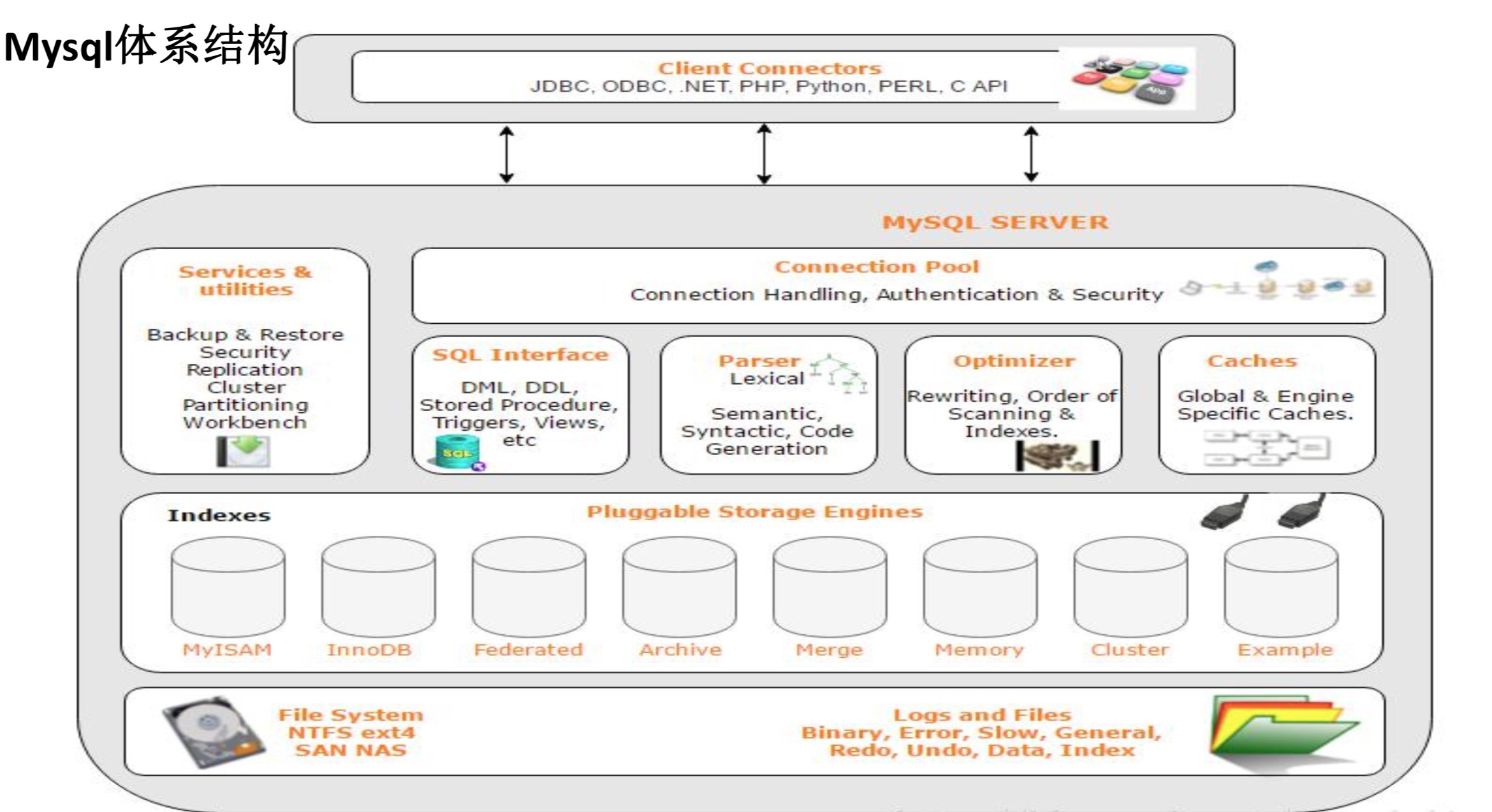
一、mysql体系结构
二、mysql索引
1、定义
索引是为了加速对表中的数据行的检索而创造的一种分散存储的数据结构
2、索引的实现
mysql的索引是由存储引擎来实现,不同的存储引擎实现方式不同。
3、存放位置
一般是存放在磁盘中
4、作用
- 减少扫描的数据行
- 可以把随机IO变成顺序IO
- 可以帮助我们在分组、排序等操作时,避免使用临时表
5、索引结构
我们都知道mysql的索引使用B树来实现的,那么为什么会考虑B树,不考虑其他数据结构呢?
5.1 首先我们来看普通的二叉树。
普通的二叉树不是绝对平衡的,会有一个问题,如下图:
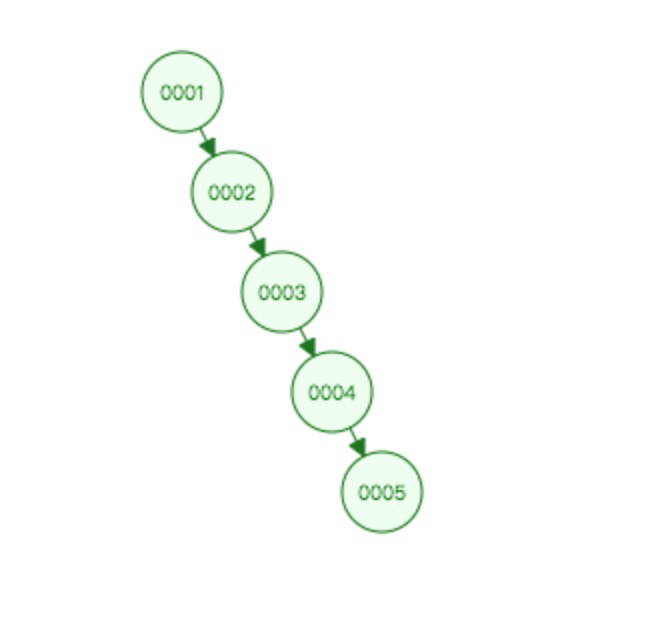 它有可能会形成一个链表,这样就失去了二叉树的优势,需要遍历查找,性能查。
它有可能会形成一个链表,这样就失去了二叉树的优势,需要遍历查找,性能查。 5.2 那么如果我们选择平衡二叉树呢?如下图:
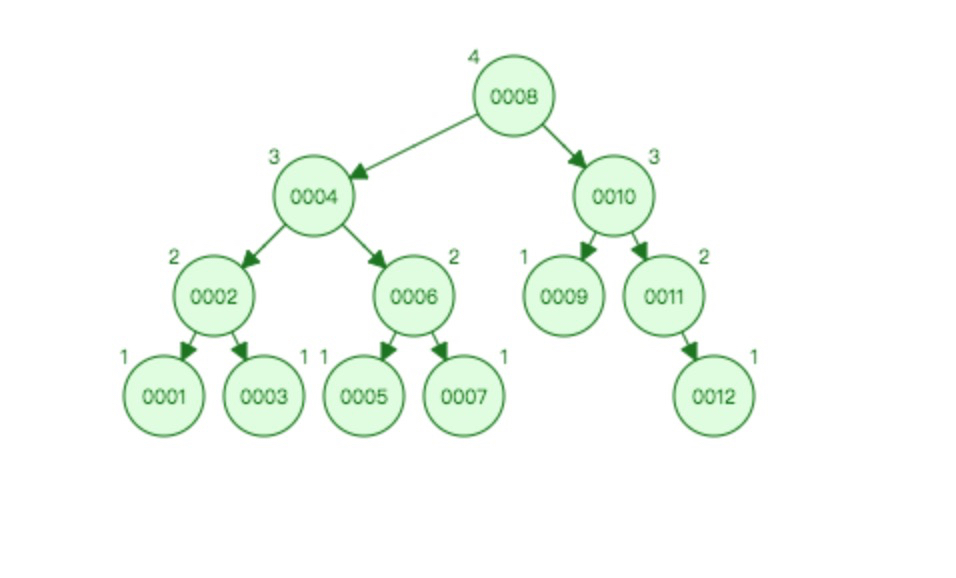
 平衡二叉树没有普通二叉树可能会形成链表的问题,但是它还有其他的问题。
平衡二叉树没有普通二叉树可能会形成链表的问题,但是它还有其他的问题。 a、它太深了
- 这里的太深是指树的高度,大家不要想歪了~
- 如果在数据量很大的情况下,这棵树的高度很可能成千上万,因此它的IO次数也会很频繁,会严重影响性能
b、它太小了
- 太小指的是每一个磁盘块(节点)保存的数据量太小了
- 没有利用好操作磁盘IO的数据交换特性(4K)
- 没有利用好磁盘IO的预读能力(空间局部性原理)
这里解释下为什么说没有利用好。
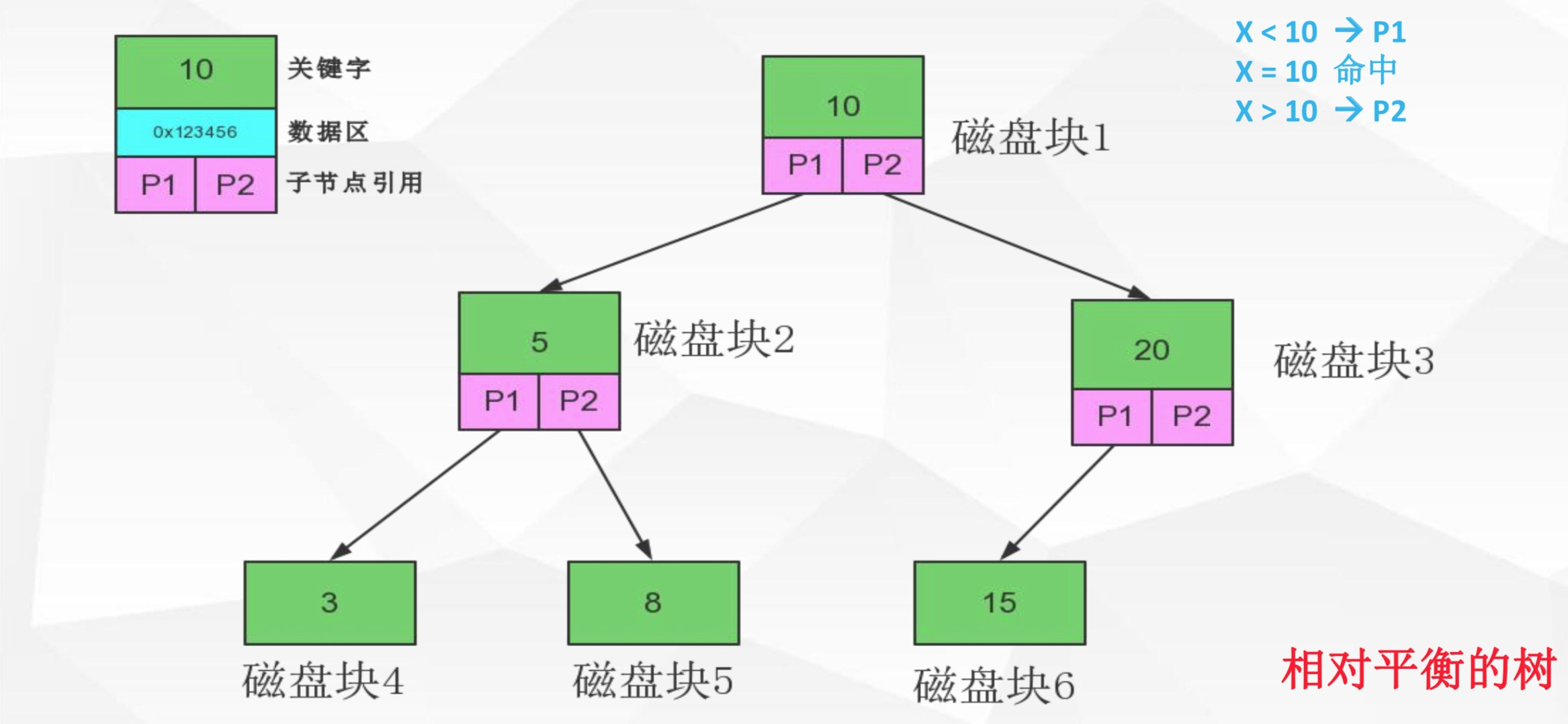
1、操作系统磁盘IO的数据交换一次默认是4KB大小,但是我们的节点里面存储的数据远远小于4KB,即我们进行了一次IO但是没有完全利用这次IO的数据交换大小,造成浪费。 2、操作系统磁盘IO具备预读能力,是什么意思呢?比如我们要读取一张20KB大小的jpg图片,我们第一次读了4KB的头内容,操作系统会认为我们可能需要接下来的16KB的剩余内容,所以会一次性把剩余的内容都传输给我们。5.3 那么如果我们选择B-Trees即多路平衡查找树呢?如下图:
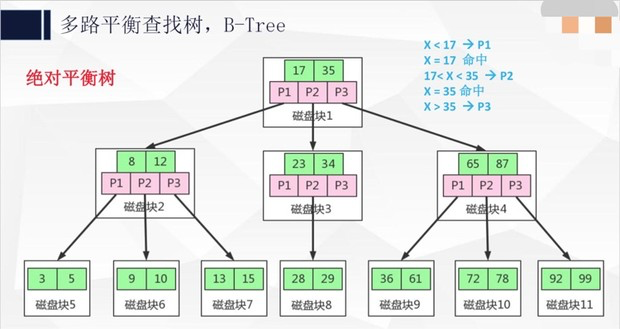
5.4 最后来看下B+Trees即加强版多路平衡查找树。如下图:

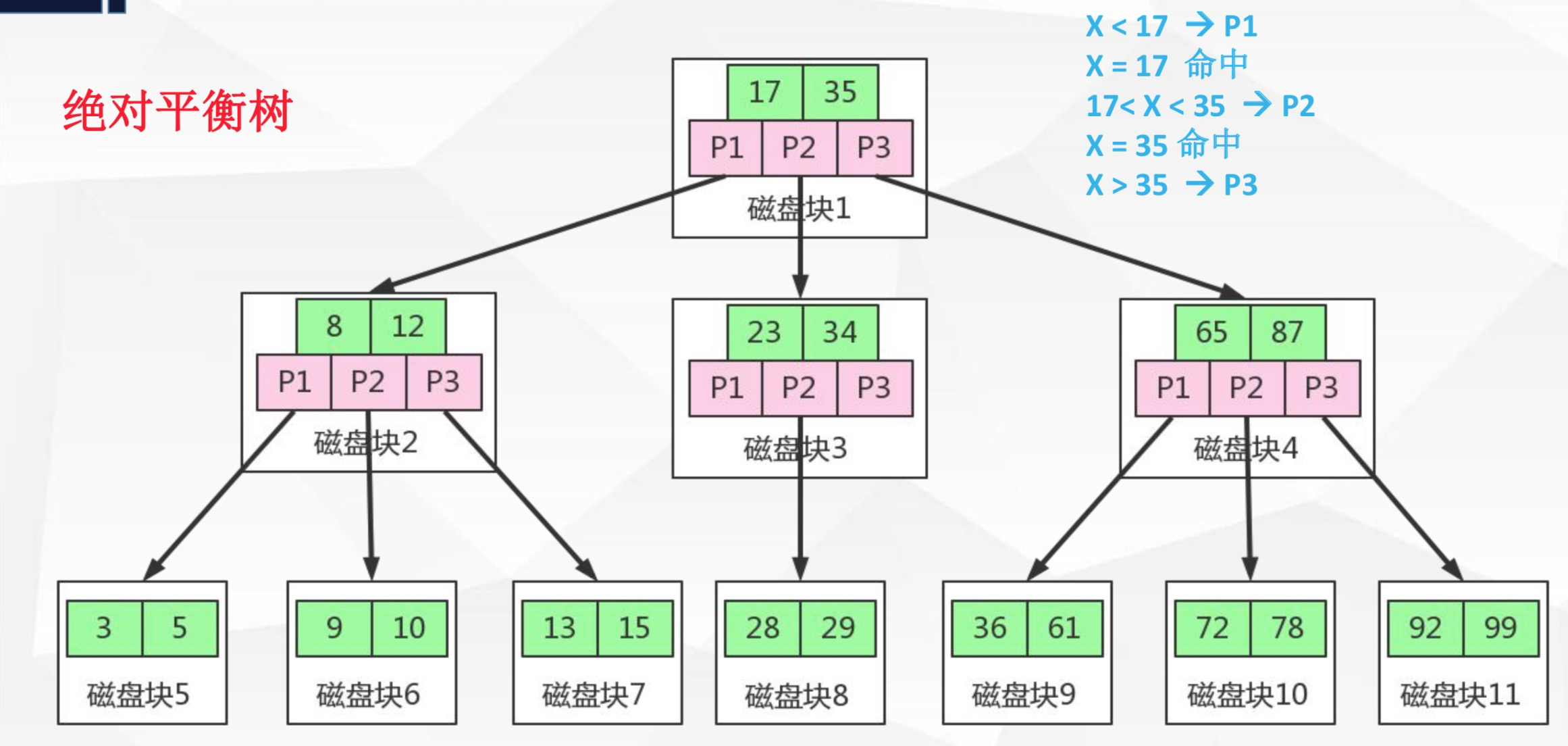 它有以下几个特点:
它有以下几个特点: - 采用闭合区间
- 非叶子节点不保存数据,只保存关键字和子节点的引用
- 关键字对应的数据保存在叶子节点中
- 叶子节点是顺序排列的,并且相邻的节点具有顺序引用的关系
5.5 那么我们为什么要采用B+Trees呢?
- 拥有多路的优势
- 扫表能力强
- 磁盘IO能力强
- 排序能力强
- 查询能力更稳定
这里我解释下为什么说B+Trees的查询能力更稳定:
B-Trees可能扫秒到第一层就返回,也可能扫秒到最后一层才返回。可能很快也可能很慢。 B+Trees每次都要扫面到最后一层,因此速度更加稳定。6、B树在存储引擎中的实现方式
6.1、Myisam
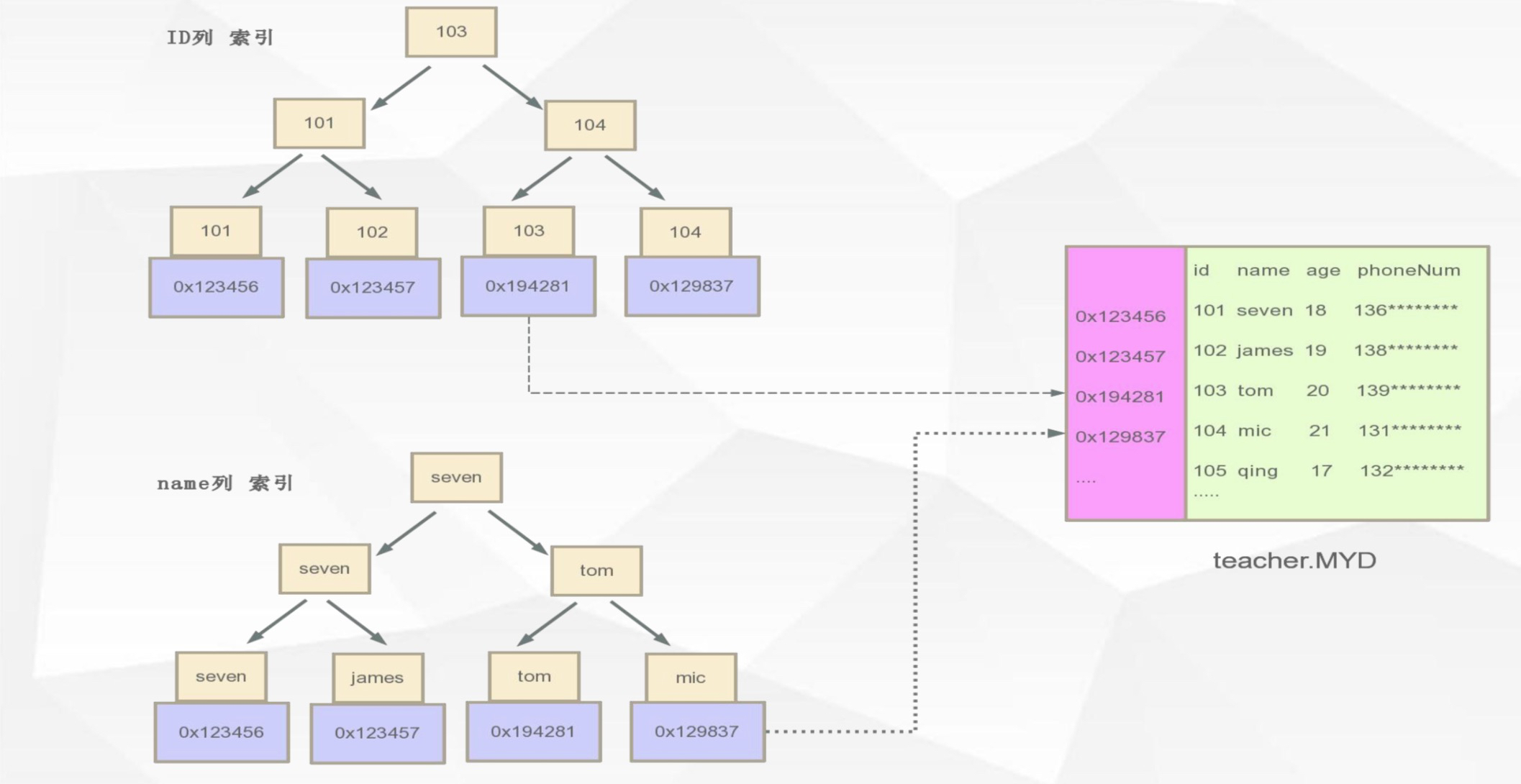
- 非聚簇索引,数据和索引分别存储。
- 索引文件xx.MYI
- 数据文件xx.MYD
- 叶子节点保存的是引用地址而非数据
6.2、InnoDB
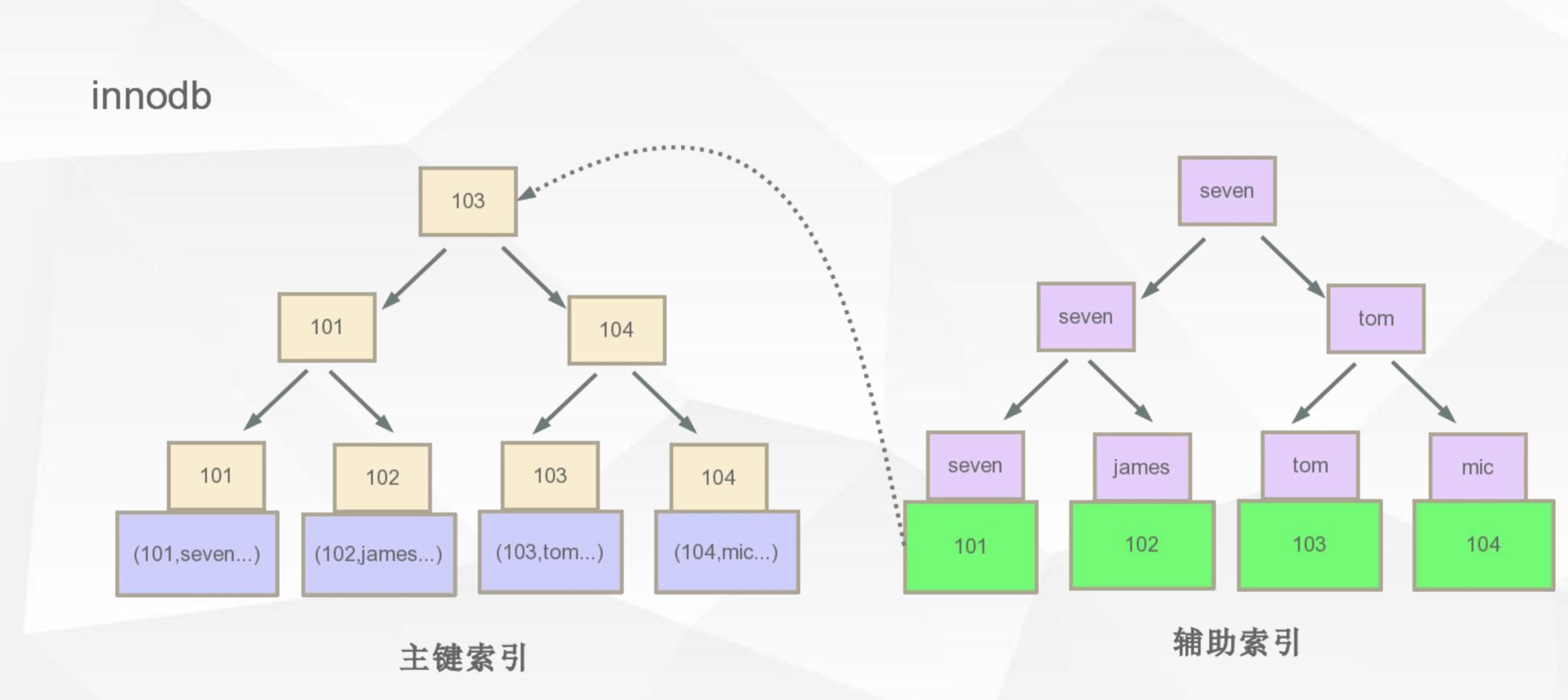
- 聚簇索引,数据和索引保存在一起
- 文件xx.ibd
- 在叶子节点保存对应的所有数据
- 以主键索引来组织数据,没有主键的话,会帮我们隐式创建主键索引
- 辅助索引不存地址,存主键,这样便于维护
7、列的离散性
- 列的离散性在索引中是一种很重要的指标。
- 列的离散性 x = count(distinct col) : count(col)
- 比例越大,离散性越高,选择性就越好
- 下面我们看个例子来理解:
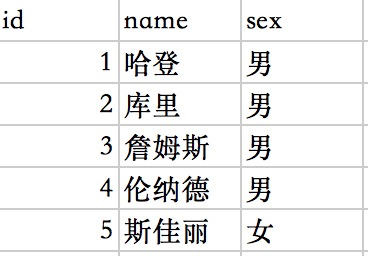
- name的列的离散性 x1 = 5 : 5 = 1
- sex的列的离散性 x2 = 2 : 5 = 0.4
- x1>x2,所以sex的列的离散性低,可选择性差。
- 可选择性差是什么意思呢?比如有如上100W的数据,现在我们要查找sex=男的,那么在索引中我们可选择的范围太大了,因为只有男或者女,查询效率就很低
- 在mysql查询优化器中,如果列的离散性低的话,可能就不走索引,直接全表扫描
8、联合索引
8.1 建立联合索引的原则:
- 经常用的列优先
- 离散性高的列优先
- 宽度小的列优先
8.2 适用性:
- 如果不是最左匹配,则无法使用联合索引
- where id = ? and age > ? 第二列是范围判断的,走联合索引
- where id > ? and age = ? 第一列是范围判断的,不走联合索引
9、覆盖索引
-
定义:如果查询的列可以通过索引节点的关键字直接返回,则称之为覆盖索引
-
ex: index_name
覆盖:select name from user where name= ? 非覆盖:select * from user where name= ? -
覆盖索引可以减少数据库IO操作,不用再走到B树的叶子节点获取数据,而是在子节点就可以获取关键字进行返回。
10、建立索引的原则
- 索引不易建多:维护B+Trees成本高,插入、更新、删除等操作要做很多逻辑判断
- 索引列的长度不易过长:会影响B+Trees的路数,进而影响IO效率